Like most progressive political organizations, Working Families Party (WFP) reluctantly uses EveryAction, the volunteer-management side of NGPVAN, as our CRM for keeping track of our activists and donors. EveryAction has many issues, support is difficult to access, and its issues are unlikely to dramatically improve since its recent acquisition by private equity and subsequent mass layoffs.
One common issue with EveryAction is the proliferation of duplicate contacts. Staff working with EveryAction will search for a contact and notice that two or more contacts for the same person seem to exist. This creates a problem with getting accurate metrics out of EveryAction and also introduces confusing workflow issues for any staff who want to add or update contact attributes. Which contact should be updated? Pick either one? Update both?
Contacts can be manually merged in the EveryAction web app, but the process is slow and untenable if duplicates exist at scale. And for any organization that uses EveryAction for several years or longer, duplicates can certainly go to scale. At WFP we estimate that somewhere between 5%-10% of our EveryAction contacts are duplicates.
Bonterra, the organization behind EveryAction, is aware of the common issue with duplication and offers a paid service to deduplicate your data for you. The fee for the service is exorbitant and a questionable offering when dealing with duplicates is arguably more of a bug in the product than a feature to be upsold on.
We decided to tackle deduplicating our data ourselves and want to share our process and learnings with the rest of the progressive organizations who are still locked in to this product.
To tackle the proliferation of duplicates in EveryAction, we needed to answer a few key questions:
- Where are the duplicates coming from? // How can we mitigate the creation of new duplicates?
- Which contacts are duplicates? // How can we match and merge existing duplicates?
Whence ??
Where are the duplicates coming from?
Before we dive in, I will note that I did this engineering work and wrote this blog post about a year ago, and some small things have changed with EveryAction’s duplicate handling in that time. Some of the details I found through trial and error may not still behave in exactly the same way, although most of the behavior described here should still hold.
When data is loaded into EveryAction, EveryAction attempts to validate the new data with an existing contact record using one of four combinations of data fields.
- first name, last name, date of birth
- first name, last name, phone number
- first name, last name, email
- first name, last name, street number, street name, zipcode
If a match is found on any of those sets of attributes, EveryAction will load associated data to that existing matched contact. Good! If no match can be found, a new contact is created. Makes sense.
There are a few bugs in this process, however, that cause issues with matching.
If a phone or email that can’t be parsed as valid are provided in the set of contact attributes, EveryAction will fail to make a match, even if there are enough other attributes available to make a match.
If none of the preferred supplementary contact attributes are available, EveryAction will make a new contact. If you only ever obtain first names and last names for certain contacts and regularly load that data into EveryAction, you will make duplicates of those same contacts each and every time.
And of course, people’s contact details and even their names change over time, typos arise all the time, etc.
How can we mitigate the creation of new duplicates?
To mitigate the creation of new duplicates, we needed to improve the performance of the “matching” step that happens before data is loaded onto a matched or created contact.
Data is loaded into our EveryAction instance in three ways:
- Some tools like Mobilize have built-in integrations with EveryAction and load data directly.
- We use the API to programmatically sync data from other platforms (like ActBlue and Spoke) that don’t have direct integrations.
- Sometimes staff do a bulk upload manually through the web app.
I assume that all three methods use the same logic to make matches, but I’ve only personally verified the behavior of the API.
The EveryAction API offers two endpoints for finding contact matches. - /find will search for a match, and raise various errors on failure
to find a match. - /findOrCreate will search for a match, and create a new contact if
no match is found. This endpoint always returns a contact, and
there’s no simple way to know if the contact was a match or is a new creation.
/findOrCreate is very convenient for getting a sync up and
running. Many of our legacy syncs to EveryAction used that
endpoint. However, to mitigate the creation of new duplicates, we need
to improve the default matching behavior. We can achieve this
improvement by separating the “find” and “create” steps, and adding
more flexibility into the matching logic before reverting to new contact creation.
In pseudo-code, this looks like moving from:
contact_data = {...}
van_id = find_or_create_van_id(contact_data)
to
contact_data = {...}
van_id = find_van_id(contact_data)
if not van_id:
van_id = try_harder_to_find_van_id(contact_data)
if not van_id:
van_id = create_van_id(contact_data)
If we don’t default to creating a new contact whenever EveryAction fails to find a match, we have the opportunity to add some more flexible and intelligent matching logic into the process.
There are several strategies we’ve developed that seem to make many
reliable matches that EveryAction fails to make. We are continuing to
monitor the creation of new contacts to identify other heuristics that
can be used in a function like try_harder_to_find_van_id().
- If a middle initial or middle name gets input as part of a first name, EveryAction will fail to make a match. e.g. “Barbara E. Walters, 858-555-5555” will not match to “Barbara Walters, 858-555-5555”. Removing characters from a first name after an initial space can more reliably match contacts.
- Apostrophes and quote marks are not reliably parsed by source platforms or EveryAction. e.g. “Mark O’Donnell, 619-555-5555” will not match with “Mark ODonnell, 619-555-5555” or “Mark O`Donnell, 619-555-5555”. Removing apostrophes and quote marks from names seems to improve matching.
- Cleaning and validating phone numbers, emails, and street numbers and zipcodes before attempting to make a match improves matching. e.g. “John Green, 750-555-3499a, jgreen @hotmail.co” will not normally match to “John Green, 750-555-3499, jgreen@hotmail.com”
A working example version of a python function built on top of the
parsons package that implements the logic described above can be
seen here.
By cleaning and validating data and making other improvements to matching heuristics, we can more reliably find matches to our source data before defaulting to creating new contacts.
Whomst ??
Which contacts are duplicates?
The problem of identifying records in a dataset that refer to the same person is called “entity resolution,” or more specifically “identity resolution” if your duplicated entities are people.
Identity resolution is a nearly universal data quality issue. Depending on how data is gathered, it is usually very hard or impossible to track individuals over time with complete certainty. There are very few contact attributes that are not subject to change over time. In the context of community organizing, we only generally gather basic contact attributes like name, email, phone, and address. All of those contact attributes are subject to change, and sometimes frequent change. This makes matching contact data back up into a consolidated list of individual persons difficult.
The problem of identifying which contacts in our data our duplicates of each other is essentially a problem of identity resolution.
Luckily, because this is a common business problem, there are many resources available to help address the issue. In particular, the free and open source packages splink and zingg appeared promising to our team. Both packages train and deploy machine learning models developed from academic statistics research into identity resolution.
Machine learning models can make powerful, accurate predictions, but may be non-deterministic and can obscure the logic used under-the-hood to make their predictions. Without some kind of baseline, it would be hard for us to tell how well these models were performing in identifying duplicates in our data. To improve our understanding of our problem, we first developed a series of SQL models to identify duplicates according to a set of reliable, deterministic criteria.
SQL Models
We made two sets of criteria for identifying duplicates at different levels of confidence. “High confidence matches” were matches that we felt so confident of, we were willing to merge without manual review. “Medium confidence matches” are mostly duplicates, but contain many false positives that we want to weed out with either manual review or future revisions of our SQL models.
High confidence matches
Our high confidence criteria are based on the same criteria that EveryAction uses. By design there should be few or zero duplicates on the contact sets that EveryAction uses to make matches, but we found about 3% of our contacts were duplicates on these canonical contact attributes. (Our support contact at EveryAction thinks these are likely due to ongoing or legacy bugs in the matching system).
We expand this set by cleaning and normalizing the contact attributes before they are matched.
- Names are cleaned of all non-alphabet or space characters, trimmed of leading or trailing spaces
- All characters are lower-cased
- First names are reduced to the first word before a space
This expanded set includes an additional ~0.3% of our total contacts.
Medium confidence matches
Our medium confidence criteria are a bit more expansive, and represent different heuristics we developed based on looking through our data to try and guess at what patterns were generating duplicates.
One very common pattern we noticed was contacts recorded with a first initial as a first name. For example, “Barbara Smith, 555-555-5555” may have a duplicate “B Smith, 555-555-5555”.
Another common pattern we saw was a match in email usernames with either a change or typo in email domain. e.g. “barbsmith1972@yahoo.com” should match “barbsmith1972@gmail.com” or “barbsmith1972@yahoo.co”.
This medium confidence model mimics the high confidence model, but expands the match criteria to catch these first initial matches and email username matches.
The other common pattern we catch in this model is matches on first name and last name when these other contact attributes are all null. As discussed above, when contact data with only first name and last name are loaded to Every Action, a new contact is created every time. We want to find and merge all such examples.
When we filter out overlaps with the high confidence model, this medium confidence model finds an additional ~1% of our total contacts.
We do expect that some of these are false positives, and we want to manually review all of these medium confidence matches before programmatically merging them.
Review
Using these clear and deterministic criteria, we find that 3-4% of our total contacts may be duplicates. Likely some portion of these are false positives, but we also expect that we capture only a small portion of the total duplicates that fail to match on these particular criteria.
The contacts identified by our SQL models give us a useful baseline for comparison to our machine learning models. We can now estimate their performance by comparing the overlap in contacts identified by each.
Machine Learning Models
While deterministic criteria may work for identifying many potential duplicates, there are likely many more whose similarity is less easily defined. Typos or changes across multiple fields may make comparison difficult, and even with fuzzy matching we would still want to differentially weight matches on different attributes. For example, an exact match on date of birth is worth more than an exact match on zipcode.
The free and open source packages splink and zingg were both designed by data scientists with way more expertise than myself in this problem area, and I’m inclined to trust that expertise and implement their solutions to our identity resolution problem.
Both packages will take a dataset and output matches with confidence scores. However, especially at first, I need to understand the threshold at which the confidence of splink or zingg compares to my own confidence. My initial approach is to send all matches above a certain lower bound on confidence for manual review before programmatically merging any of them. So I am treating all these matches as “medium confidence”.
zingg looks a bit shinier, but splink looks easier to implement. zingg and splink can both run on Apache Spark, but splink can also run on duckdb. splink’s duckdb backend was impressively capable of running predictions on our entire contacts table on my 16GB RAM laptop in a few minutes.
I set up an automated workflow for splink to run as a Prefect flow and load its predictions to a redshift table. The splink model needs some configuration to tell it which records to compare and how different attributes should be compared. I based my configuration off their official tutorial which some minor changes to reflect what we know about EveryAction contact matches.
splink makes a LOT of predicted matches. We set our lower confidence bound around 0.3 (on a scale from 0-1) and about 20% of the contacts in our database are predicted to be duplicates at this level of confidence. We expect many of these to be false positive matches, and can select some subset of the top matches to manually validate.
| | sql confidence | count | splink max | splink min | splink mean | splink median |\n|—-:|:————————-|————:|——————-:|——————-:|———————:|————————:|\n| 0 | high | 16562 | 1 | 0 | 0.997379 | 1 |\n| 1 | medium | 8935 | 1 | 0 | 0.949009 | 0.958971 |\n| 2 | 0 | 6933193 | 1 | 0.300087 | 0.9452 | 0.944315 |
This table compares how splink matches line up against our SQL models. You can make your own conclusions, but I have a few key takeaways:
- splink makes several orders of magnitude more match predictions than my SQL models
- splink confidence levels trend quite high, with a median of 94% confidence across all ~7 million predicted matches. Likely there is a huge difference in the quality of matches between 99% confidence and 94% confidence
- splink confidence does seem to track with my SQL models. My high confidence SQL matches correspond to a median splink confidence of 100%, down to 95.9% for my medium confidence SQL matches, and then down again to 94.4% for matches not identified by my SQL models.
Some manual review of splink’s top matches that aren’t covered by my SQL models validates the expected behavior. splink makes matches between contacts that are clearly duplicated on manual review, but don’t fall into the deterministic criteria I set in my SQL models. Some of these scenarios:
- A nickname is used in one contact, making a match on firstname fail
- A small typo exists in an email address or street address
- A contact’s last name changed, perhaps due to marriage
splink makes more match predictions than we can easily handle, and seems to be performing well enough that we don’t need to bother setting up zingg.
Manual Validation
Merging contacts is an irreversible operation, so it is important to be quite confident about matches before executing a merge. For matches identified by the high confidence SQL model defined above, we feel confident about a programmatic merge. However, for all the matches identified by our “medium confidence” SQL model, and all matches identified by our splink implementation, we want to execute a manual validation before merging.
To manually validate contacts, we have set up a web application that pulls matches and all associated contact details. Contacts and their details are displayed side by side, and a user selects whether the match is valid, invalid, or unclear. The validation workflow is somewhat boring and tedious, but quite fast. Using the web app, a single person can validate 500-1000 matches in an hour.
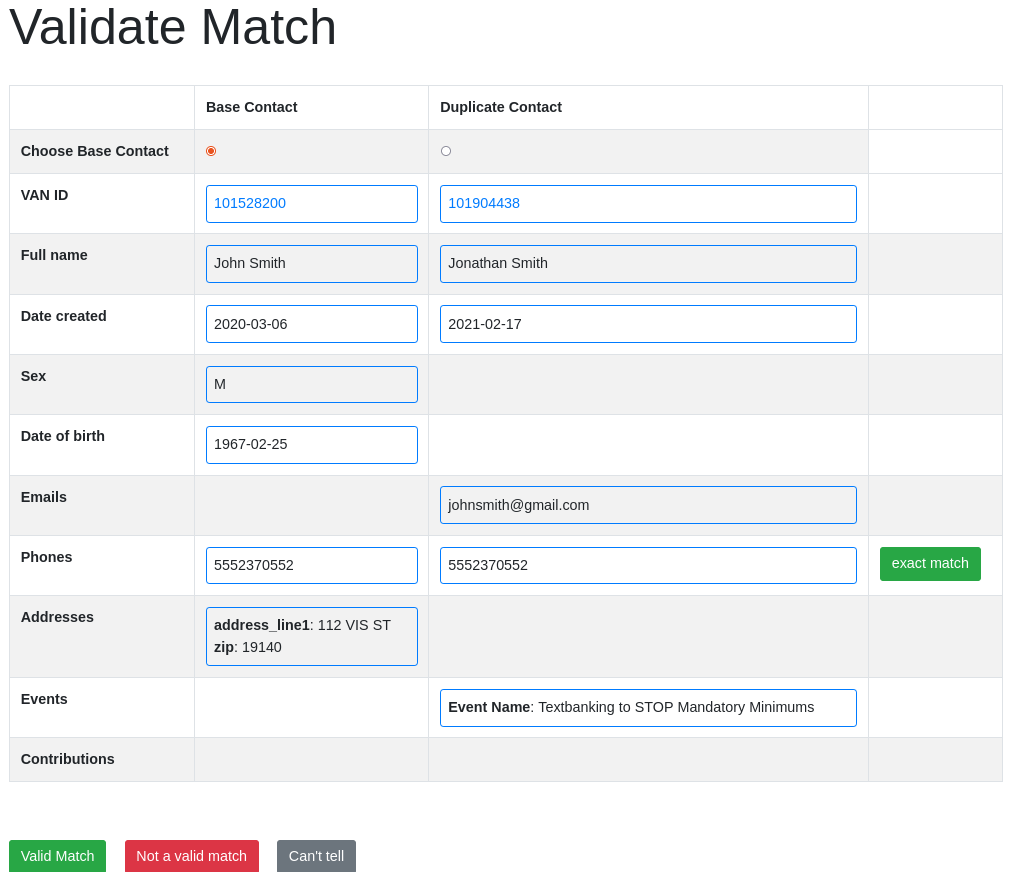
Over time, using the web app to manually validate contacts helps to generate new “high confidence” heuristics that can be used to identify matches without needing a manual review step. For example, we may realize we have a large number of contacts with first name “undefined” and last name “undefined”, and we can investigate those further and purge them from the database. Another example is that we have found that contacts that are matched on first name and last name but have no additional contact details defined can be merged with high confidence.
Whereunto ??
EveryAction should take responsibility for the management of duplicate contacts as a critical feature in their CRM. However, in lieu of them fixing this problem, it is possible for users with sufficient engineering capacity to understand the problem and implement a fix on our own.
We use SQL queries to identify matches at two levels of confidence, and we use splink to identify another batch of duplicates. We feel confident we can programmatically merge higher confidence SQL matches without review, but we want to manually validate all the other matches. We can use a web application to make the manual validation a quick and easy process and manually validate thousands of potential matches in just a few days.
High confidence and validated matches are accumulated in a database
table and staged for processing by a programmatic merge script. This
script iterates through each match and executes an API call to the
EveryAction API endpoint /people/{vanid}/mergeInto.
We run our SQL models, splink, and the programmatic merge on a weekly basis to identify and merge duplicates. Manual validation happens on a rolling basis and all validated contacts are aggregated and merged on the next schedule merge flow.
If you want to know more about any of this, feel free to reach out. I also tentatively plan on making an affordable plug-and-play version of this application available to TMC members in early 2025 - let me know if you might be interested in beta testing this.